Dies ist nun das tägliche des Anwendungsentwicklers. Zu unterscheiden sind vier verschiedene Datenbank:
Datenbankmodelle unterscheiden
Hierarchisches Modell
Daten werden in einer Baumartigen Struktur organisiert, wobei jeder untergeordneten Entität genau einer übergeordneten Entität zugeordnet ist. Beispiel eines Hierarchisches Modell:
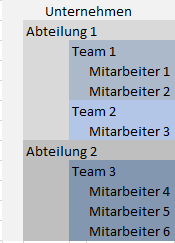
Ein Unternehmen ist in Abteilungen aufgeteilt. Beispiel Abteilung 1, die Technik.
Die Technik ist aufgeteilt in 2 Teams, einmal Entwicklung (Team 1) und Support (Team 2).
Abteilung 2 könnte z.B. Vertrieb mit dem Vertriebsteam sein.
Netzwerkmodell
Ähnlich dem Hierarchischen Modell, aber jede untergeordnete Entität kann mehreren übergeordneten Entitäten zugeordnet sein, was eine komplexere Struktur ermöglicht:

Wie an dem nebenstehenden Beispiel zu sehen, schaut es nahezu gleich aus. Mit dem Unterschied, das hier der Mitarbeiter 1 aus dem Team 1 der Abteilung 1 zusätzlich in der Abteilung 1 sein Dienst verrichtet.
Relationales Modell
Daten werden in Tabellen (Relationen) organisiert, wobei jede Tupel (Zeile) einen Datensatz darstellt und jedes Attribut (Spalte) einen Datentyp darstellt.
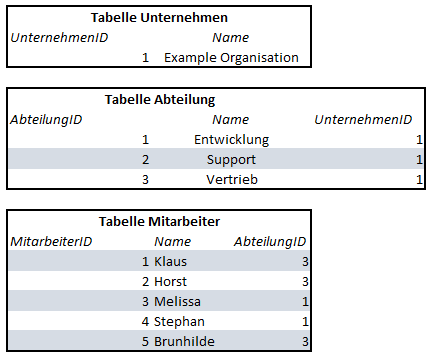
Beispiel einer Relationalen Datenbank.
Wir haben eine Firma, der Firma sind Abteilungen zugeordnet und den Abteilungen sind Mitarbeiter zugeordnet.
In diesem relationalen Modell haben wir 3 Tabelle, welche durch einen Fremdschlüssel (UnternehmenID, AbteilungID und MitarbeiterID) miteinander Verknüpft sind.
Diese Verknüpfung (Relation) ermöglicht es uns, aus allen drei Tabellen Informationen abzufragen.
Objektorientiertes Modell
Dies ist für viele lernenden das wohl schwerste Modell.
Ein objektorientiertes Datenbankmodell verwendet Objekte, ähnlich wie in der objektorientierten Programmierung. Jedes Objekt kann Attribute (Daten) und Methoden (Funktionen) enthalten und definieren.
Hier ein Beispiel für ein Objektorientiertes Modell (C#):
///////////////////////////////////////////////////////////////////////////////////////////////////////////
//Klasse Mitarbeiter
using System;
public class Mitarbeiter
{
public int MitarbeiterID { get; set; }
public string Name { get; set; }
public string Position { get; set; }
public int AbteilungID { get; set; }
public Mitarbeiter(int mitarbeiterID, string name, string position, int abteilungID)
{
MitarbeiterID = mitarbeiterID;
Name = name;
Position = position;
AbteilungID = abteilungID;
}
public void AnzeigenInfo()
{
Console.WriteLine($"Mitarbeiter: {Name}, Position: {Position}, AbteilungID: {AbteilungID}");
}
}
///////////////////////////////////////////////////////////////////////////////////////////////////////////
// Klasse Abteilung
using System;
using System.Collections.Generic;
public class Abteilung
{
public int AbteilungID { get; set; }
public string Name { get; set; }
public List<Mitarbeiter> Mitarbeiter { get; set; }
public Abteilung(int abteilungID, string name)
{
AbteilungID = abteilungID;
Name = name;
Mitarbeiter = new List<Mitarbeiter>();
}
public void AnzeigenInfo()
{
Console.WriteLine($"Abteilung: {Name}, AbteilungID: {AbteilungID}");
foreach (var mitarbeiter in Mitarbeiter)
{
mitarbeiter.AnzeigenInfo();
}
}
}
///////////////////////////////////////////////////////////////////////////////////////////////////////////
// Programm
using System;
public class Program
{
public static void Main()
{
// Abteilungen erstellen
Abteilung marketing = new Abteilung(101, "Marketing");
Abteilung it = new Abteilung(102, "IT");
// Mitarbeiter erstellen und zu Abteilungen hinzufügen
Mitarbeiter elsbeth= new Mitarbeiter(1, "Elsbeth", "Manager", 101);
Mitarbeiter noah= new Mitarbeiter(2, "Noah", "Entwickler", 102);
Mitarbeiter lea= new Mitarbeiter(3, "Lea", "Designer", 101);
marketing.Mitarbeiter.Add(alice);
marketing.Mitarbeiter.Add(carol);
it.Mitarbeiter.Add(bob);
// Informationen anzeigen
marketing.AnzeigenInfo();
it.AnzeigenInfo();
}
}Daten organisieren und speichern
Normalisierung
Der Prozess der Strukturierung einer Datenbank zur Reduzierung von Redundanz und Verbesserung der Datenintegrität.
Ich verwende hier ein extremes Beispiel der Normalisierung in einer Relationalen Datenbank.

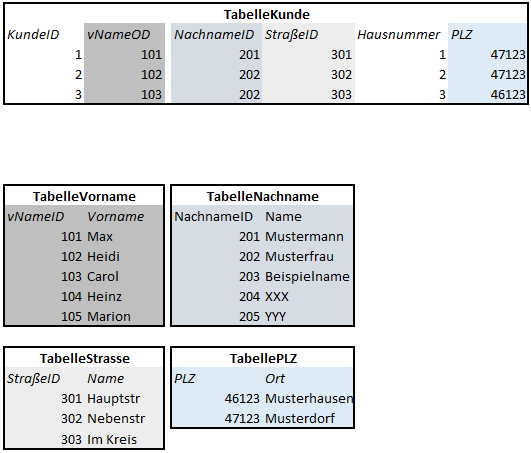
Beispiel einer nicht normalisierten Datenbank in der Kunden gespeichert werden.
In der Tabelle kann gesehen werden, das einige Einträge redundant sind. Auch redundante Einträge verbrauchen
Speicherplatz, was in der kleinen Tabelle kein Problem ist.
Beispiel einer Normalisierten Datenbank.
Sieht erstmal nach größerer Arbeit aus. Besonders weil es nur 3 Datensätze sind.
Anhand der Tabelle TabelleKunden das nur noch verweise für die Daten des Kunden gespeichert werden.
Dies bedeutet, egal wieviele Kunden wir mit dem Namen „Musterfrau“ besitzen, benötigt dieser Name nur für 1x speichern
den Speicherplatz, danach nur noch den Speicherplatz des Datentype der ID.
Mit dieser kleinen Beispieltabelle ist er Aufwand etwas groß, aber bei der Datenbank des Kraftfahrbundesamtes
(Punktesammelstelle in Flensburg) sieht es wieder anders aus.
Tabellen und Beziehungen
Verwende Tabellen, um verschiedene Datentypen zu organisieren und definiere Beziehungen zwischen diesen Tabellen (z.B. Primär- und Fremdschlüssel).
Als Beispiel verwende ich wieder das Beispiel der Firma, Abteilung und Mitarbeiter. Diese Tabelle ist nicht zu 100% vollständig, veranschaulicht aber die Beziehungen zwischen Tabellen.
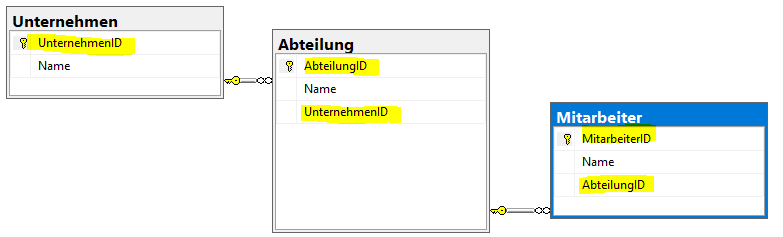
Kurze Erklärung zur oben abgebildeten Datenbank:
Die Datenbank besteht aus 3 Tabellen (Unternehmen, Abteilung und Mitarbeiter), diese enthält eigentlich nur den Namen. Normalerweise oder in einem echten Programm kommen da noch sehr viel mehr Attribute und Relationen zu stande. Aber ich denke zum veranschaulichen von Relationen ist ein kleinere Beispiel einfacher für Auszubildene zu verstehen.
In jeder Tabelle ist in dem Namen des ersten Feldes (Attribut) der Name der Tabelle und ein mit ID. So läßt es sich schnell und einfach veranschaulichen das es sich um einen einmaligen (unique) Key handelt, der Primary Key. Einige Datenbankdesigner nennen den Primarykey aber auch oft mit PK_[Tabellenname]_ID (Beispiel: PK_Unternehmen_ID). In der Grafik habe ich in den Tabellen Abteilung und Mitarbeiter jeweils zusätzlich 1 Feld gelb markiert, dies ist der Foreignkey. Dieser Schlüssel zeigt auf einem Datensatz der jeweils anderen Tabelle.
Tabelle Abteilung zeigt auf einem Datensatz aus der Tabelle Unternehmen, Tabelle Mitarbeiter zeigt auf einem Datensatz der Tabelle Abteilung.
Der Foreignkey (Fremdschlüssel) wird verwendet um eine Beziehung zu einer anderen Tabelle herzustellen, dabei verweist der Foreignkey auf dem Primarykey der referenzierten Tabelle.
Beispiel:
Die Abteilung ‚Entwicklung‘, verweist auf dem Unternehmen.
Ein/e Mitarbeiter/in ‚Müller‘, besitzt eine Referenz auf der Abteilung ‚Entwicklung‘.
Referenzen
- 1:1 Eins-zu-Eins Beziehung: Eine Zeile einer Tabelle kann genau einer Zeile der Referenzierten Tabelle zugeordnet werden.
Beispiel: Jeder besitzt genau 1 Personalausweis. - 1:N Eins-zu-viele Beziehung: Eine Zeile einer Tabelle ist mit mehreren Zeilen der Referenzierten Tabelle zugeordnet.
Beispiel: Eine Abteilung hat viele Mitarbeiter. - N:M Viele-zu-viele Beziehung: Mehrere Zeilen einer Tabelle kann auch mehrere Zeilen einer anderen Tabelle zugeordnet sein.
Beispiel: Ein Projekt kann mehrere Mitarbeiter haben, und 1 Mitarbeiter kann mehrere Projekte haben.
In derigen Darstellung kleinen Datenbank ist es nicht erforderlich, dem Mitarbeiter erneut eine Beziehung zum Unternehmen zuzuweisen. diese Datenbank so wurde, dass ein Mitarbeiter einer Abteilung und die Abteilung Unternehmen zugeordnet ist, ist es per SQL, Mitarbeiter eines Unternehmens abzufragen.
Beispiel SQL:
SELECT Name FROM Mitarbeiter WHERE AbteilungID IN(
SELECT AbteilungID FROM Abteilung WHERE AbteilungID IN (
SELECT UnternehmenID WHERE Name = 'Beispielfirma'
)
)